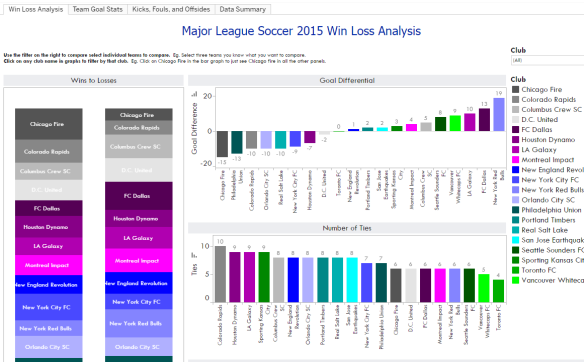
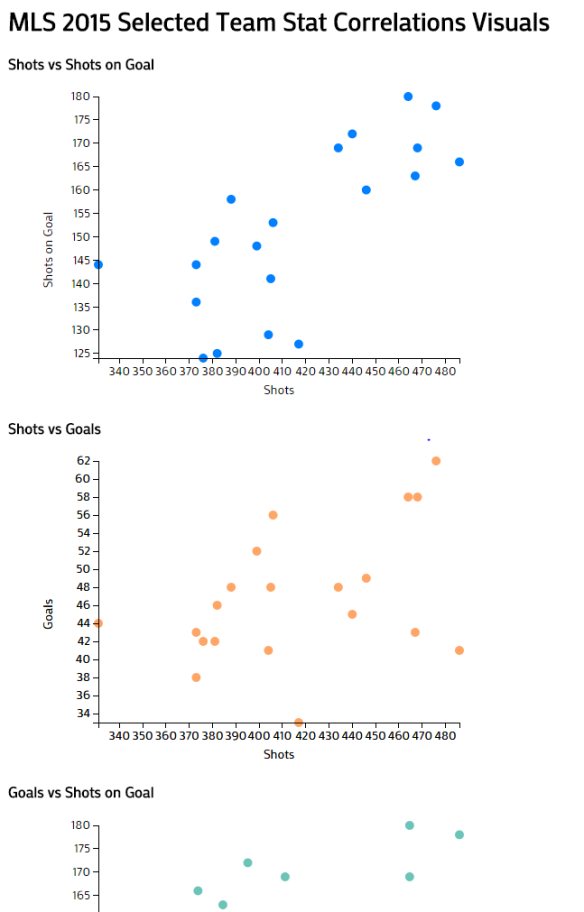
Books Read
The Memo: What Women of Color Need to Know to Secure a Seat at the Table
Articles Read
- ‘People in the advertising and marketing industry and the modern mainstream have different ‘moral foundations’ and (unconscious) intuitions about what is right and wrong”
- “As a leading social psychologist, Haidt has been at the forefront of popularising the idea of WEIRD (Western, Educated, Industrialised, Rich and Democratic) morality and psychology. Haidt identifies five moral foundations and shows that, although WEIRD morality is dominant in political, cultural, media and professional elites in the United States, WEIRD people are actually statistical outliers whose moral foundations are unrepresentative of the general population.”
- The need is to combine empathy with efficiency in advertising
Why We shouldn’t trust our gut instinct
- Ad agency employees are “anywheres” with mobility and exposure to other cultures. This is a fundamental difference to 50% of the UK in terms of values to Somewheres where identities take a firm local root.
- Tldr: Agency employees and MBA employees do not think like mainstream they sell to
- “There is no universal ‘one size fits all’ model of perception and reasoning that goes across cultural differences
WTF IS OPERATIONS? #SERVERLESS
- “Operations is the sum of all of the skills, knowledge and values that your company has built up around the practice of shipping and maintaining quality systems and software. It’s your implicit values as well as your explicit values, habits, tribal knowledge, reward systems. Everybody from tech support to product people to CEO participates in your operational outcomes, even though some roles are obviously more specialized than others.”
- A critical path when considering trade-offs in going serverless is resiliency from a user’s perspective and preserving that. Figure out what your core differentiators are, and own those.
- You still need to understand your storage systems – there’s still a server underneath so many abstractions.
Orchestration vs. Choreography
- Orchestration is a central process that controls different web services and coordinates the execution of different operations on the Web services involved in the operation
- Choreography is when each web service knows exactly when to executive it’s operations and with whom to interact.
- Orchestration is more flexible paradigm
Scheduling a Meeting the Right Way
- Know the hierarchy, ask what works best for them first or do the team approach first
- Put fences around time – don’t ask blindly for times that work
- Keep paper trail
- Serverless architectures are application designs that make use of 3rd party Backend as a Service or in managed ephemeral containers that Functionas as a Service. Serverless removes the need for a traditional always-on component that may reduce operational cost, complexity, and engineering hours with the trade-off of relying more on vendors and possibly immature support services.
- Benefits:
- More flexible to change, adding features requires less changes in architecture
- Fundamentally, you can run back-end code without managing owner server systems or applications. The vendor handles resource provisioning and allocation
- FaaS do not require coding to a specific framework or library
- You can bring up entire applications up and down to respond to an event
- Drawbacks:
- Requires better distributed monitoring capabilities. More moving pieces to manage and done by external parties
- Vendor management becomes a much more important function in a serverless org
- Multitenancy problems creep
- Security concerns, configurations become much more paramount
Managing communications effectively and efficiently
- Check-in with stakeholders about understanding project
- What is working in how we communicate with you about the project?
- What is not working or is not effective in our communications?
- Where can we improve our communications with you?
- How to figure out fine balance between too much and too little communications
- Who needs to know what information?
- How often must that information be communicated/shared?
- By what means will information be communicated/shared?
- Figure out stakeholders and their repsonsibilities on each project to tailor
All the best engineering advice I stole from non-technical people
- Most things get broken around the seems. Use the 100:10:1 approach
- Brainstorm 100things that could go wrong
- Pick 10on that list that feel like the most likely and investigate them
- Find the 1 critical problem you’re going to focus on.
- Understand why they hired you – always ask yourself what am I asked to be the expert here? (In my case, translating and ruthlessly prioritizing and trading off features so that a finished product that makes money gets into the end users hands in a form where they can do that for the org)
- Figure out an observability that works for your team, not just facetime and don’t get into cycle of over attempts at over optimization and trust degradation. “Replacing trust with process is called bureaucracy.”
Why Companies Do “Innovation Theater” Instead of Actual Innovation
- “People who manage processes are not the same people as those who create product. Product people are often messy, hate paperwork, and prefer to spend their time creating stuff rather than documenting it. Over time as organizations grow, they become risk averse. The process people dominate management, and the product people end up reporting to them.”
- “In sum, large organizations lack shared beliefs, validated principles, tactics, techniques, procedures, organization, budget, etc. to explain how and where innovation will be applied and its relationship to the rapid delivery of new product.”
- “Process is great when you live in a world where both the problem and solution are known. Process helps ensure that you can deliver solutions that scale without breaking other parts of the organization… These processes reduce risk to an overall organization, but each layer of process reduces the ability to be agile and lean and — most importantly — responsive to new opportunities and threats.”
How Does The Machine Learning Library TensorFlow Work?
- Tensorflow allows for deep neural network models
- Tensorflow lets you display your computation as a data flow graph and visualize it using the in-built tensorboard
- You build a graph by defining constants, variables, operations, and then executing. Nodes represent operations and Edges are the carriers of data structures (tensors) where the output of one operation (from one node) becomes the input for another operation.
Whatever Happened To The Denominator? Why We Need To Normalize Social Media
- The denominator, especially in social media and data science around it is almost nonexistent so there’s no sense of how big a dataset is or if it’s growing or shrinking. We can’t normalize it, and therefore, can’t really understand it.
- Analyzing Twitter data is a frequent misuse of this, eg. interpreting retweets as a behavioral proxy for some sort of engagement about breaking news that is flawed when many are just forwards
- “We tout the accuracy and precision of our algorithms without acknowledging that all of that accuracy is for naught when we can’t distinguish what is real and what is an artifact of our opaque source data…. We tout the accuracy and precision of our algorithms without acknowledging that all of that accuracy is for naught when we can’t distinguish what is real and what is an artifact of our opaque source data.”
- Prework, Clearly defined goals, and meeting time managed against agenda
- Debrief once in awhile about meetings
- Institute no tech meetings when needed
How to choose the right UX metrics for your product
- Quality of user experience: Good old HEART framework
- Happiness: measures of user attitudes, often collected via survey. For example: satisfaction, perceived ease of use, and net-promoter score.
- Engagement: level of user involvement, typically measured via behavioral proxies such as frequency, intensity, or depth of interaction over some time period. Examples might include the number of visits per user per week or the number of photos uploaded per user per day.
- Adoption: new users of a product or feature. For example: the number of accounts created in the last seven days or the percentage of Gmail users who use labels.
- Retention: the rate at which existing users are returning. For example: how many of the active users from a given time period are still present in some later time period? You may be more interested in failure to retain, commonly known as “churn.”
- Task success: this includes traditional behavioral metrics of user experience, such as efficiency (e.g. time to complete a task), effectiveness (e.g. percent of tasks completed), and error rate. This category is most applicable to areas of your product that are very task-focused, such as search or an upload flow.
- Don’t necessarily need a metric in every one of HEART category, but it’s a useful framework to apply to your particular product
- Goals Metrics Signals – match to your user experience, grid with a HEART framework
- Goals
- Metrics
- Signals
The secrets to running project status meetings that work!
- Agenda need to be defined, team members need to be prepared, time management, handling input and topic control
- Focus on both the what (the content) and how (the meeting is run)
- Look back and forward on the meeting in a two week or appropriate interval to make sure it’s not a rehash and things are moving forward
The First Thing Great Decision Makers Do
- Commit to your default decision upfront as a habit, meaning framing the context before you seek data. You need to be a decision criteria set that is informed by background knowledge and a hypothesis.
- simple example of max price you’re will to pay before you see a price
- acknowledging sunk costs upfront
- The pitfall otherwise is “data-inspired decision making” that can be riddled with confirmation bias or misinterpretations
- A question to ask if, there is no data, what will by decision be and what’s that based on? If there is data, what is the magnitude of evidence to sway me from my default decision?
The ultimate guide to remote meetings 2019
- Build a virtual water cooler to encourage rapport and build relationships, eg. Slack channels. Make some time for small talk in beginning
- Agenda setting
- Key talking points
- Meeting structure (for example, when and for how long you plan to discuss each talking point)
- Team members/teams that will be in attendance
- What each team member/team is responsible for bringing to the meeting
- Any relevant documents, files, or research
- Actions for next meeting
- Deliverables and next steps
- Who’s responsible for following up on each item or task
- When those deliverables are due
- When the next meeting or check-in will be
- Make sure everyone has a job and include the introverts
What SaaS Product Managers Need to Know About Customer Onboarding in 2019
- Every successful user journey consists of four main parts:
- Converting your website visitors
- Unleashing the “aha moment”.
- User activation – when user feels value
- Customer adoption – contact with secondary features and start using product
- Personalization as key and using right products to streamline process and need for strong customer support/portals/kb
- Take advantage of the Zeigarnik effect – people have the tendency to remember uncompleted tasks, eg checklists, breadcrumbs of more tasks
- Key question ““What do I need to do to make a bigger difference to the company?”
- “If your manager visibly doesn’t believe in your capacity to get to the next level regardless of what you do, find a new manager; your career is at a dead end where you are.”
- The only piece of leverage that really matters is a counteroffer
- Range of techniques for altering or augmenting behavior of an OS, apps, or other software components by intercepting function calls, messages, or events passed through components. Code that handles such intercepted function calls, events, or messages, of called a hook.
- Methods:
- Source modification – modifying source of executable or library before app is running
- You can also use a wrapper library and make own oversion of a library that an application loads
- Runtime modification: inserting hooks at runtime, eg. modify system events or app events for dialogs
- Source modification – modifying source of executable or library before app is running
Webhook vs API: What’s the Difference?
- “Both webhooks and APIs facilitate syncing and relaying data between two applications. However, both have different means of doing so, and thus serve slightly different purposes.”
- Webhook: Doesn’t need to be a request, data is sent whenever there is new data available
- Usually performs smaller tasks, eg. new blog posts for CMS
- API: Only does stuff when you ask it to.
- Tends to be entire frameworks, eg. Google Maps API that powers other apps
Treehouse
- Concatenation operator joins two pieces of text ||
- Single quotes should be used for String literals (e.g. ‘lbs’), and double quotes should be used for identifiers like column aliases (e.g. “Max Weight”)
- Example
- SELECT first_name || ‘ ‘ || last_name || ‘ ‘ || ‘<‘ || email || ‘>’ AS to_field FROM patrons;
- Examples of using functions:
- — SELECT LENGTH(<column>) AS <alias> FROM <table>;
- SELECT username, LENGTH(username) as length FROM customers;
- — LOWER(<value or column>)
- SELECT LOWER(title) as lowercase_title, UPPER(author) as uppercase_author FROM books;
- — SUBSTR(<value or column>, <start>, <length>)
- SELECT name, SUBSTR(description, 1, 35) || “…” AS short_description, price FROM products;
- — REPLACE(state, <target>, <replacement>)
- SELECT street, city, REPLACE(state, “California”, “CA”), zip FROM addresses WHERE REPLACE(state, “California”, “CA”) = “CA”;
- — SELECT LENGTH(<column>) AS <alias> FROM <table>;
- — COUNT(<column>)
- SELECT COUNT(DISTINCT category) FROM products;
- — SELECT <column> FROM <table> GROUP BY <column>;
- SELECT category, COUNT(category) as product_count FROM products GROUP BY category;
- — SUM(<column>)
- — having keyword works on aggregates after GROUP BY before ORDER BY
- SELECT SUM(cost) AS total_spend, user_id FROM orders GROUP BY user_id ORDER BY total_spend DESC
- SELECT SUM(cost) AS total_spend, user_id FROM orders GROUP BY user_id HAVING total_spend > 250 ORDER BY total_spend DESC;
- — AVG(<column>)
- SELECT user_id, AVG(cost) AS average_orders FROM orders GROUP BY user_id;
- — MAX(<numeric column>) MIN(<numeric column>)
- SELECT AVG(cost) AS average, MAX(cost) as maximum, MIN(cost) as minimun, user_id FROM orders GROUP BY user_id;
- SELECT name, ROUND(price*1.06,2) AS “Price in Florida” FROM products;
- –DATE(“now); in sqlite
- SELECT * FROM orders WHERE status = “placed” AND ordered_on = DATE(“now”);